utf-8 - encodage de caractères
Unicode supporte presque tous les existantsjeux de caractères. La meilleure forme de codage de jeu de caractères Unicode est le codage utf-8. Il fournit la compatibilité avec ASCII, la résistance à la corruption de données, l'efficacité et la facilité de traitement. Mais à propos de tout dans l'ordre.
Formes de codage
Les ordinateurs fonctionnent avec des nombres non seulement commeobjets mathématiques abstraits, mais en tant que combinaisons d'unités de stockage et de traitement d'octets d'information de taille fixe et de mots de 32 bits. La norme de codage doit en tenir compte pour déterminer la manière dont les caractères sont représentés par des nombres.
Dans les systèmes informatiques, les entiers sont stockés danscellules de mémoire dans la taille de 8 bits (1 octet), 16 ou 32 bits. Chaque forme de codage Unicode détermine quelle séquence de cellules mémoire représente un entier correspondant à un caractère particulier. La norme fournit trois formes différentes de codage des caractères Unicode: les blocs 8, 16 et 32 bits. En conséquence, ils sont appelés utf-8, UTF-16 et UTF-32. Le nom UTF signifie format de conversion Unicode. Chacune des trois formes de codage est un moyen égal de représenter les caractères Unicode, a des avantages dans diverses applications.
Ces encodages peuvent être utilisés pourreprésentation de tous les caractères Unicode. Ainsi, ils sont entièrement compatibles pour des solutions pour différentes raisons en utilisant différentes formes de codage. Chaque encodage peut être uniquement converti en l'un des deux autres sans perte de données.

Principe de non-imposition
Chacune des formes de codage Unicode est conçue avecen tenant compte de l'inadmissibilité du chevauchement partiel. Par exemple, Windows-932 génère des caractères à partir d'un ou deux octets de code. La longueur de la séquence dépend du premier octet, de sorte que les valeurs de premier octet dans la séquence de deux octets et un seul octet ne se croisent pas. Cependant, les valeurs de l'octet unique et de l'octet de fermeture de la séquence peuvent être les mêmes. Cela signifie, par exemple, que lors de la recherche du caractère D (code 44), vous pouvez le trouver par erreur en entrant la deuxième partie de la séquence de deux octets du caractère "D" (code 84 44). Pour déterminer quelle séquence est correcte, le programme doit prendre en compte les octets précédents.
La situation devient plus compliquée si le premier et le dernierles octets vont correspondre. Cela signifie que pour inverser l'ambiguïté, une recherche inversée sera effectuée jusqu'au début du texte ou une séquence de code non ambiguë. Ce n'est pas seulement inefficace, mais pas protégé contre les erreurs possibles, car un mauvais octet suffit à rendre le texte entier illisible.
Le format de conversion Unicode évitede ce problème, car les valeurs de l'unité de stockage principale, de fermeture et d'information unique ne correspondent pas. Pour cette raison, tous les codages Unicode conviennent à la recherche et à la comparaison, ne donnant jamais un résultat erroné en raison de la coïncidence de différentes parties du code de caractère. Le fait que ces formes d'encodage respectent le principe de non-affectation les distingue des autres codages multi-octets d'Asie de l'Est.
Un autre aspect de la non-intersection des codages Unicodeest que chaque personnage a des limites clairement définies. Cela élimine le besoin d'analyser un nombre indéterminé de caractères précédents. Cette caractéristique des encodages est parfois appelée auto-synchronisation. La distorsion d'une unité de code entraîne la distorsion d'un seul caractère et les caractères environnants restent intacts. Dans le format de conversion 8 bits, si le pointeur se réfère à un octet commençant par 10xxxxxx (en codage binaire), une à trois transitions inverses sont nécessaires pour trouver le début du caractère.

Cohérence
Unicode Consortium soutient pleinement tous3 formes de codages. Il est important de ne pas s'opposer à utf-8 et Unicode, car tous les formats de conversion sont des implémentations tout aussi légitimes des formes de codage de caractères Unicode.
Octet-orientation
Pour représenter le symbole UTF-32, vous avez besoin d'une unité de code 32 bits correspondant au code Unicode. UTF-16 - d'une à deux unités de 16 bits. Et utf-8 utilise jusqu'à 4 octets.
L'encodage utf-8 a été créé pour la compatibilité avecsystèmes orientés octets basés sur ASCII. La plupart des logiciels et des technologies de l'information existants ont longtemps reposé sur la représentation de symboles sous la forme d'une séquence d'octets. De nombreux protocoles dépendent du codage ASCII inchangé et utilisent ou évitent les caractères de contrôle spéciaux. Un moyen facile d'adapter Unicode à de telles situations consiste à utiliser un codage 8 bits pour représenter les caractères Unicode équivalents à n'importe quel caractère ASCII ou caractère de contrôle. Pour cela, le codage utf-8 est destiné.
Longueur variable
utf-8 est un encodage de longueur variable composé deUnités de stockage d'informations de 8 bits dont les bits de poids fort indiquent la partie de la séquence à laquelle appartient chaque octet. Une plage de valeurs est allouée pour le premier élément de la séquence de code, l'autre pour les éléments suivants. Ceci garantit un codage disjoint.

ASCII
L'encodage utf-8 prend entièrement en charge les codes ASCII(0x00-0x7F). Cela signifie que les caractères Unicode U + 0000-U + 007F sont convertis en un seul octet 0x00-0x7F utf-8 et deviennent ainsi indiscernables de l'ASCII. De plus, pour éviter toute ambiguïté, les valeurs 0x00-0x7F ne sont plus utilisées dans les octets de la représentation de caractères Unicode. Pour coder des symboles non-idéographiques autres que ASCII, une séquence de deux octets est utilisée. Les symboles de la plage U + 0800-U + FFFF sont représentés par trois octets, et ceux supplémentaires avec des codes supérieurs à U + FFFF nécessitent quatre octets.
Champ d'application
L'encodage utf-8 est généralement préféré dans le protocole HTML et similaire à celui-ci.
XML est devenu le premier standard avec un support completencodages utf-8. Les organisations impliquées dans la normalisation, aussi, le recommandent. Le problème de prise en charge dans les adresses URL autres que les caractères ASCII a été résolu lorsque le consortium W3C et le groupe d'ingénierie IETF ont accepté d'encoder toutes les URL exclusivement dans utf-8.
La compatibilité avec ASCII facilite la transition vers un nouveaulogiciel. Avec utf-8, la plupart des éditeurs de texte fonctionnent, y compris JEdit, Emacs, BBEdit, Eclipse et Notepad du système d'exploitation Windows. Aucune autre forme de codage Unicode ne peut se vanter d'un tel soutien des outils.
L'avantage de l'encodage est qu'ilconsiste en une séquence d'octets. Avec les chaînes utf-8, il est facile de travailler en C et dans d'autres langages de programmation. C'est la seule forme de codage qui ne nécessite pas le marquage de l'ordre des octets de nomenclature ni la déclaration de codage en XML.

Auto-synchronisation
Dans un environnement utilisant un traitement de caractères de 8 bits, comparé aux autres codages multi-octets, utf-8 présente les avantages suivants:
- Le premier octet de la séquence de code contient des informations sur sa longueur. Cela augmente l'efficacité de la recherche directe.
- Il est plus facile de trouver le début du caractère, puisque l'octet initial est limité à une plage fixe de valeurs.
- Il n'y a pas d'intersection de valeurs d'octets.
Comparaison des avantages
utf-8-encoding est compact. Mais lors de l'application pour l'encodage des caractères est-asiatiques (chinois, japonais, coréen, en utilisant des caractères chinois) des séquences de 3 octets sont utilisés. De plus, le codage utf-8 est inférieur à d'autres formes de codage par la vitesse de traitement. Un tri de chaîne binaire produit le même résultat qu'un tri binaire Unicode.
Schéma d'encodage de caractères
Le schéma de codage de caractères consiste en un formulairecodage de caractères, et une méthode d'arrangement octet par pixel d'unités de code. Pour déterminer le schéma d'encodage par le standard Unicode, l'utilisation de la marque d'ordre d'octet initiale (BOM, marque d'ordre Byte) est fournie.
Lorsque la nomenclature est activée dans utf-8, la fonction d'étiquetten'est limité que par l'indication de l'utilisation de la forme de codage. Il n'y a pas de problèmes pour déterminer l'ordre des octets dans utf-8, puisque sa taille d'unité de codage est d'un octet. L'utilisation de la nomenclature pour ce formulaire de codage n'est ni obligatoire ni recommandée. La nomenclature peut apparaître dans les textes convertis à partir d'autres codages qui utilisent la marque d'ordre des octets, ou pour la signature d'encodage utf-8. C'est une séquence de 3 octets d'EF16 BB16 BF16.
Comment régler l'encodage utf-8
En HTML, le codage utf-8 est défini à l'aide du code suivant:
˂head˃
Httpmeta http-equiv = "Content-Type" content = "texte / html; jeu de caractères = utf-8" ˂
En PHP, le codage utf-8 est spécifié en utilisant la fonction header () au tout début du fichier après avoir défini la valeur du niveau de sortie d'erreur:
˂? Php
error_reporting (-1);
header ("Content-Type: text / html; jeu de caractères = utf-8");
Pour se connecter aux bases de données MySQL, l'encodage utf-8 est défini comme suit:
˂? Php
mysql_set_charset ("utf8");
Dans les fichiers CSS, le codage de caractères utf-8 est spécifié comme suit:
@charset "utf-8";
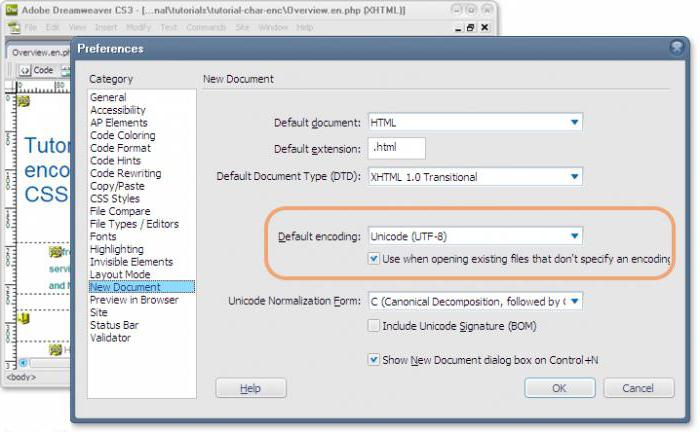
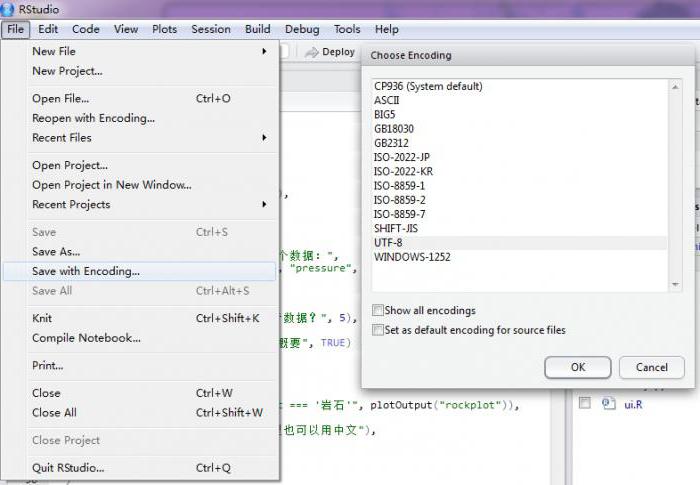
Lorsque vous enregistrez des fichiers de tous types, sélectionnezencoder utf-8 sans nomenclature, sinon le site ne fonctionnera pas. Pour ce faire, dans le programme DreamWeave, vous devez sélectionner l'option de menu "Modifications - Propriétés de la page - Titre / Codage", changer le codage en utf-8. Ensuite, vous devez recharger la page, décochez la case "Connecter les signatures Unicode (BOM)" et appliquer les modifications. Si un texte sur la page ou dans la base de données a été entré par un autre formulaire de codage, il doit être ressaisi ou recodé. Lorsque vous travaillez avec des expressions régulières, il est obligatoire d'utiliser le modificateur u.
Vous pouvez également enregistrer le fichier au format utf-8 dans le bloc-notes de Windows. Après avoir sélectionné l'élément de menu "Fichier - Enregistrer sous ...", définissez le format d'encodage nécessaire et enregistrez le fichier au format utf-8.
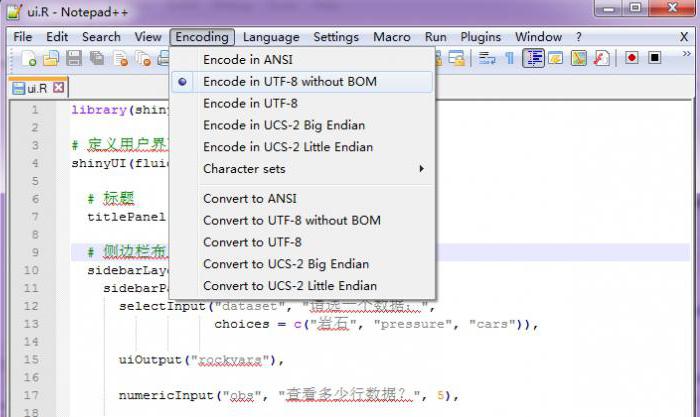
Dans l'éditeur de texte Notepad ++, si le codage est différent de utf-8, modifiez le codage et enregistrez-le dans le codage utf-8 via l'option de menu "Convertir en utf-8 sans nomenclature".
Il n'y a pas d'alternative
Dans le contexte de la mondialisation, lorsque les politiques etles limites des langues sont effacées, les ensembles de symboles ayant des caractéristiques locales deviennent moins utiles. Unicode est le seul jeu de caractères qui supporte toutes les localisations. Et utf-8 est un exemple de l'implémentation correcte d'Unicode, qui:
- prend en charge un large éventail d'outils, y compris la compatibilité avec le codage ASCII;
- est résistant à la corruption de données;
- simple et efficace dans le traitement;
- ne dépend pas de la plate-forme.
Avec l'avènement de la discussion utf-8 sur la forme d'encodage ou de jeu de caractères la meilleure, ils sont devenus sans signification.
</ p>




